За три предыдущих статьи серии мы прошли путь от единственной ноды до полноценного отказоустойчивого кластера. В первой разобрали quorum-очереди и failover на Raft. Во второй — гарантии доставки: publisher confirms, manual ack, DLQ и retry. В третьей — как связывать кластеры через Federation и Shovel.
Но у любой системы есть вопрос, который встаёт после запуска: как убедиться, что она работает так, как задумано? Кластер может быть живым, но деградировавшим. Consumer может быть подключён, но не справляться с нагрузкой. При failover можно не потерять ни одного сообщения — но только при условии, что вы знаете, за чем смотреть.
Наблюдаемость (observability) закрывает цикл серии: это то, что делает HA реально рабочим в production, а не только на бумаге.
В статье
- Метрики RabbitMQ через Prometheus
- Что смотреть при failover: дашборд Grafana
- Настройка стенда мониторинга
- Продакшн-чеклист
- Заключение серии
Метрики RabbitMQ через Prometheus
RabbitMQ поставляется со встроенным плагином rabbitmq_prometheus. Никаких сторонних экспортёров не нужно: плагин входит в стандартную поставку и включается одной строкой в конфиге или через rabbitmq-plugins enable.
Плагин rabbitmq_prometheus
Плагин поднимает HTTP-эндпоинт на порту 15692 каждой ноды:
http://localhost:15692/metrics
Метрики отдаются в формате Prometheus (text/plain). Endpoint доступен без аутентификации по умолчанию — в production его стоит закрыть сетевыми политиками, чтобы не светить внутреннее состояние кластера наружу.
В demo-стенде все три ноды слушают порт 15692 и доступны Prometheus внутри Docker-сети. Наружу (
localhost:15692) проброшен толькоrabbit1— для ручной проверки через браузер или curl.rabbit2иrabbit3снаружи недоступны, но Prometheus скрейпит их по внутренним Docker-именам хостов.
return_per_object_metrics
В rabbitmq.conf включается детализация по каждой очереди:
prometheus.return_per_object_metrics = true
По умолчанию (false) плагин возвращает агрегированные метрики по всему брокеру — суммарная длина всех очередей, суммарный publish rate и так далее. Это быстро и компактно, но не позволяет видеть состояние отдельных очередей.
С return_per_object_metrics = true каждая очередь получает собственный набор метрик с лейблом queue="demo.orders". Это позволяет строить алерты и панели для конкретных очередей, видеть, какая именно очередь растёт или деградирует.
Трейдофф: детализированные метрики — это значительно больший объём данных. В кластере с сотнями очередей и несколькими нодами /metrics-endpoint может возвращать мегабайты данных при каждом скрейпе. При больших кластерах стоит взвесить, нужна ли per-object детализация для всех очередей, или достаточно агрегатов с точечной детализацией через Management API.
На нашем demo-стенде с тремя нодами и несколькими очередями return_per_object_metrics = true — разумный выбор.
Ключевые метрики
Вот метрики, за которыми важно следить в работающем кластере:
Глубина очереди — самый важный сигнал состояния системы:
| Что смотреть | Смысл |
|---|---|
rabbitmq_queue_messages_ready |
Сообщения, ждущие consumer. Монотонный рост — consumer не справляется или упал |
rabbitmq_queue_messages_unacked |
Сообщения «в пути» у consumer. Растут без уменьшения — consumer завис или prefetch слишком большой |
rabbitmq_queue_messages (total) |
Сумма ready + unacked. Общий объём «живых» сообщений в очереди |
Скорость потока — наблюдение за throughput:
| Что смотреть | Метрика | Смысл |
|---|---|---|
| Publish rate | rate(rabbitmq_queue_messages_published_total[1m]) |
Скорость входящих сообщений (msg/s). Провал — проблемы с producer или сетью |
| Deliver/Ack rate | rate(rabbitmq_queue_messages_delivered_ack_total[1m]) |
Скорость подтверждённых доставок. При manual ack = реальная скорость обработки |
Примеры PromQL для алертов:
# Publish rate по очереди demo.orders за последнюю минуту
rate(rabbitmq_queue_messages_published_total{queue="demo.orders"}[1m])
# Deliver/Ack rate
rate(rabbitmq_queue_messages_delivered_ack_total{queue="demo.orders"}[1m])
Состояние кластера — здоровье инфраструктуры:
| Что смотреть | Метрика | Смысл |
|---|---|---|
| Число живых нод | count(up{job="rabbitmq"} == 1) |
Ноды, которые Prometheus видит UP. Падение ниже большинства — критический сигнал |
| Состояние реплик quorum-очередей | Management UI / rabbitmq-queues CLI |
Нет лидера или реплики не в синке — угроза доступности; готовой Prometheus-панели в demo-дашборде нет |
Пример PromQL для алерта на потерю ноды:
# Число живых нод кластера
count(up{job="rabbitmq"} == 1)
Ресурсы ноды — предвестники проблем:
| Что смотреть | Смысл |
|---|---|
| Memory high watermark | Приближение к лимиту → брокер начнёт блокировать publishers (flow control) |
| Disk free limit | Мало места → брокер блокирует публикацию persistent-сообщений |
Что смотреть при failover: дашборд Grafana
Demo-стенд из репозитория включает Grafana с готовым дашбордом «RabbitMQ — Failover demo». Дашборд показывает поведение кластера во время сценария из первой статьи: лидер quorum-очереди убивается принудительно, Raft выбирает нового, клиенты переподключаются.
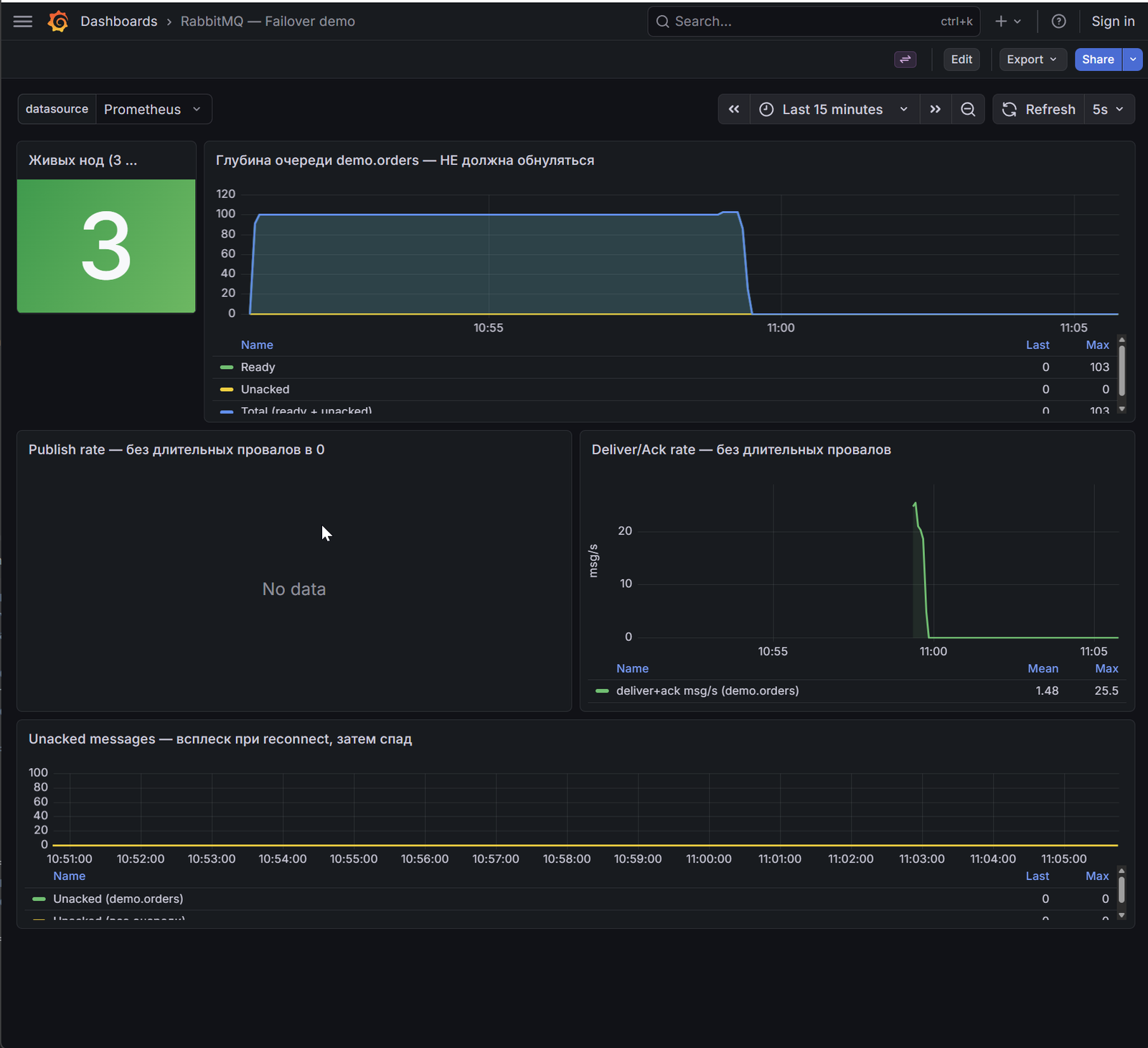
Панели дашборда и что ожидать при failover
| Панель | Что показывает | Ожидаемое поведение при failover |
|---|---|---|
| Живых нод (stat, зелёный/красный) | Число нод RabbitMQ, которые Prometheus видит UP | Падает 3 → 2, затем возвращается к 3 после восстановления |
| Глубина очереди demo.orders (timeseries) | Ready + Unacked + Total | Не обнуляется — данные не теряются |
| Publish rate (timeseries) | Скорость публикации msg/s | Кратковременный спад на 1–3 сек при переизбрании лидера Raft, затем восстановление |
| Deliver/Ack rate (timeseries) | Скорость доставки с подтверждением msg/s | Аналогично — без длительного провала |
| Unacked messages (timeseries) | Сообщения «в пути» у consumer | Всплеск при reconnect (consumer переподключается), затем спад до нуля |
Как читать каждую панель
Живых нод. Stat-панель меняет цвет: зелёный = 3 ноды, оранжевый/красный = 2 или меньше. Это первый индикатор, который меняется — ещё до того, как клиенты заметят какой-либо эффект.
Глубина очереди. Ключевая панель для наблюдения за сохранностью данных. При failover она не обнуляется — это то самое доказательство того, что quorum-очередь сохранила сообщения при смерти лидера. Если бы вместо quorum-очереди была classic-очередь на упавшей ноде, этот график показал бы обнуление.
Publish rate и Deliver/Ack rate. Вы увидите характерный провал: 1–3 секунды, пока Raft проводит выборы нового лидера. Producer с publisher confirms в этот момент не получает ack — он будет ждать таймаута или переподключения и повторит. Consumer переподключается и продолжает работать. Провал есть, но он короткий — это и есть «практически без простоя».
Unacked messages. Характерный всплеск: consumer был подключён к упавшей ноде, его соединение оборвалось, брокер вернул unacked-сообщения в очередь (ready). Consumer переподключился, получил их снова, подтвердил — всплеск схлопнулся. Это manual ack в действии: сообщения не потеряны.
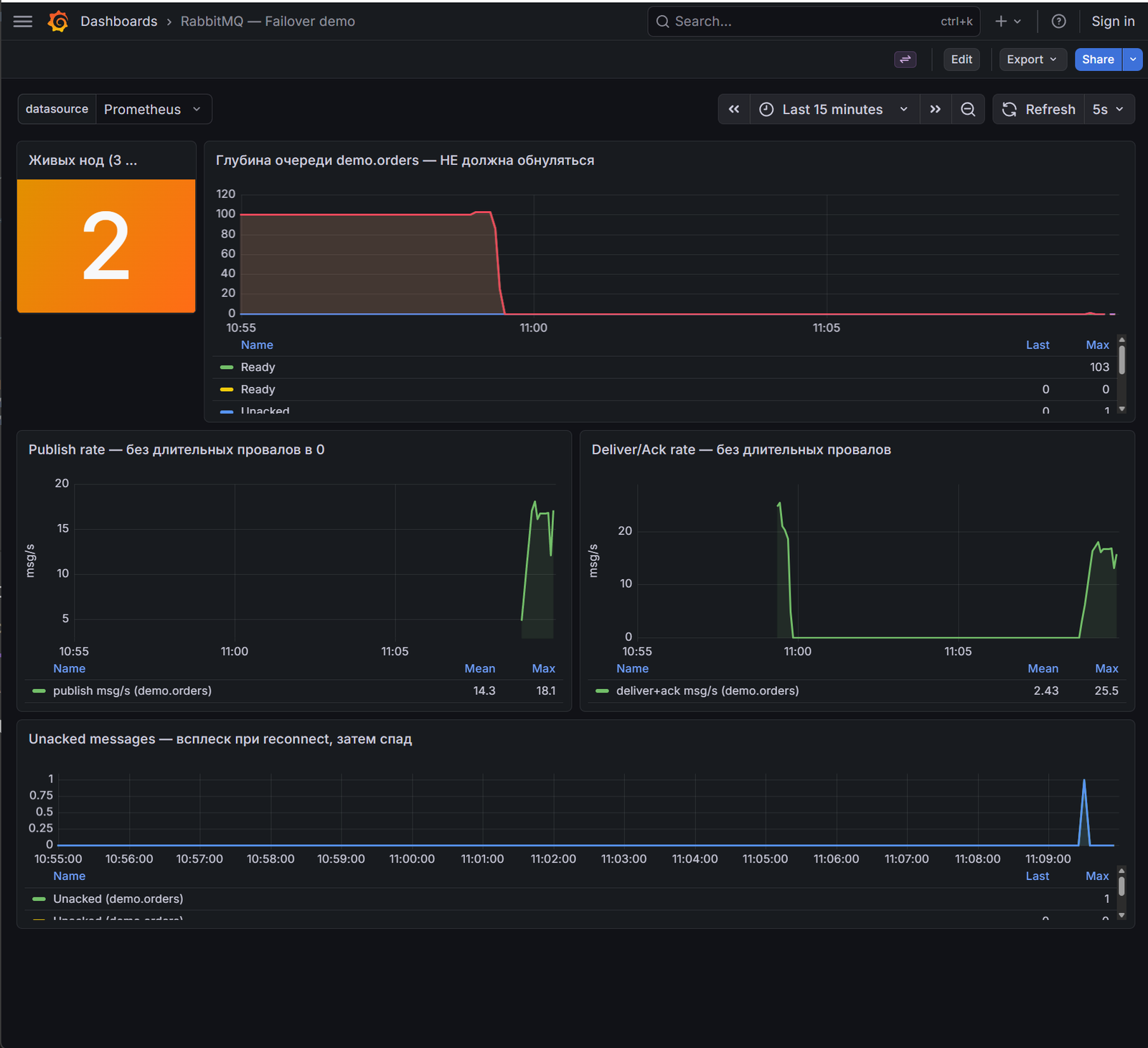
Вывод из дашборда: «кривые не обнулились, rate восстановился, данные не потерялись» — это quorum-очереди, publisher confirms и manual ack в связке.
Настройка стенда мониторинга
Demo-стенд поднимает Prometheus и Grafana вместе с кластером RabbitMQ одной командой:
# Из папки ha-cluster:
docker compose up -d
Или, если кластер уже запущен, только стек мониторинга:
docker compose up -d prometheus grafana
Доступы
| Сервис | URL | Логин |
|---|---|---|
| Grafana | http://localhost:3000 | без логина (anonymous Admin) |
| Prometheus | http://localhost:9090 | — |
| RabbitMQ metrics (rabbit1) | http://localhost:15692/metrics | — |
prometheus.yml
Prometheus скрейпит все три ноды кластера каждые 5 секунд:
# monitoring/prometheus.yml
global:
scrape_interval: 5s
evaluation_interval: 5s
scrape_configs:
- job_name: rabbitmq
static_configs:
- targets:
- 'rabbit1:15692'
- 'rabbit2:15692'
- 'rabbit3:15692'
Каждая нода отдаёт метрики независимо — это важно для наблюдения за состоянием кластера. Панель «Живых нод» считает, сколько нод Prometheus видит UP именно потому, что скрейпит все три.
Доступность снаружи в demo-стенде. Все три ноды (
rabbit1,rabbit2,rabbit3) доступны Prometheus внутри Docker-сети по порту 15692 — именно поэтому скрейп работает для всех трёх. Снаружи для ручной проверки (http://localhost:15692/metrics) открыт толькоrabbit1: уrabbit2иrabbit3порт наружу не проброшен вdocker-compose.yml.
В production стоит скрейпить все ноды, а не только одну: при потере ноды вы увидите это в Prometheus (up == 0), а не потеряете данные мониторинга вместе с нодой.
Grafana provisioning
Grafana настраивается автоматически при старте через директорию monitoring/grafana/:
monitoring/grafana/
provisioning/
datasources/ # автоподключение Prometheus как datasource
dashboards/ # автозагрузка дашбордов из папки
dashboards/
rabbitmq-failover.json # JSON дашборда «RabbitMQ — Failover demo»
Дашборд загружается автоматически — открывайте http://localhost:3000 → Dashboards → «RabbitMQ — Failover demo» и сразу видите панели.
rabbitmq.conf: включение плагина
В конфиге ноды (cluster/rabbitmq.conf в demo-стенде):
prometheus.return_per_object_metrics = true
Это единственная строка, специфичная для мониторинга. Сам плагин rabbitmq_prometheus включён в cluster/enabled_plugins. В реальном деплое убедитесь, что плагин активен:
rabbitmq-plugins enable rabbitmq_prometheus
Продакшн-чеклист
Версия RabbitMQ критична. Серия и демо-стенд проверены на RabbitMQ 4.3. В этой версии произошли принципиальные изменения по сравнению с 3.x:
- Classic mirrored queues удалены в 4.0 — только quorum queues для HA; политика
ha-modeигнорируется.cluster_partition_handlingstrategies удалены в 4.3 — поведение при сетевом разделе теперь inherent через Raft; ключ принимается, но не действует.- Native delayed retry для quorum-очередей появился в 4.3 — встроенный механизм повторных доставок без сторонних плагинов.
На более старых версиях часть пунктов чеклиста выглядит иначе или требует других настроек.
Всё, что разобрано в четырёх статьях серии, сводится к единому чеклисту. Каждый пункт — это конкретная настройка с понятными последствиями при её отсутствии.
Хранение и репликация
- Quorum-очереди — основной тип для всех продакшн-очередей:
x-queue-type=quorumпри объявлении илиdefault_queue_type=quorumна уровне vhost. Не полагаться на classic mirrored queues: в RabbitMQ 4.x они полностью удалены, политикаha-modeигнорируется. - Нечётное число нод/реплик — 3 или 5. Именно нечётность даёт однозначное большинство при Raft-выборах: 3 ноды переживают отказ 1, 5 нод — отказ 2. При 2 или 4 нодах при равном разделе выборы зависнут.
- Защита от split-brain — автоматическая (Raft). В RabbitMQ 4.3 настраиваемый partition handling (
cluster_partition_handling) удалён: меньшинство нод при сетевом разделе не имеет кворума Raft и не обслуживает запросы к quorum-очередям — split-brain исключён by design, отдельная настройка не нужна. Если в старых конфигах остался ключcluster_partition_handling— удалить (в 4.3 не действует). Именно поэтому нечётное число нод из предыдущего пункта так важно: без большинства нод кластер сам останавливает обработку, а не раздваивается. - Тип очереди не задаётся через policy-ключ
queue-type— в RabbitMQ 4.x это невалидно и не работает. Толькоx-queue-typeпри объявлении или vhostdefault_queue_type. - Три уровня durability: durable exchange + durable queue + persistent message (
delivery-mode=2). Слабое звено рвёт цепочку: если exchange transient или сообщение не persistent, рестарт ноды приведёт к потере данных, даже если очередь durable.
Гарантии доставки на стороне producer
- Publisher confirms включены — без confirms publish это «выстрелил и забыл». Брокер может принять соединение, но не записать сообщение на реплики до отказа. Confirm приходит только после того, как большинство реплик зафиксировали запись.
- Обработка nack и таймаутов с повтором — nack означает, что брокер не смог принять сообщение; publisher должен повторить с логированием. В нагруженных системах предпочтительны async/batch confirms перед sync (по одному): тот же уровень гарантии, значительно выше throughput.
Гарантии доставки на стороне consumer
- Manual ack (
autoack=false) — сообщение остаётся в очереди как unacked, пока consumer явно не вызоветAck. При падении consumer до ack брокер переотправит сообщение. Auto-ack удаляет сообщение немедленно при доставке — потеря при падении consumer гарантирована. - Идемпотентная обработка — at-least-once (manual ack) означает, что одно сообщение может быть доставлено повторно при failover или reconnect. Обработчик должен корректно работать при дублировании: дедупликация по бизнес-ключу,
INSERT ... ON CONFLICT, идемпотентные обновления. - Разумный prefetch (QoS) —
ch.Qos(N, 0, false). Не 1 (лишние round-trip’ы, низкий throughput) и не «бесконечность» (один consumer забирает всё, memory bloat). Типичное значение — десятки; в demo-стенде по умолчанию10.
Устойчивость к ошибкам обработки
- DLX/DLQ настроены — Dead Letter Exchange и Dead Letter Queue как «карантин» для сообщений, которые не удалось обработать. Без DLQ ядовитые сообщения могут бесконечно крутиться в очереди, блокируя обработку нормальных.
-
delivery-limitу quorum-очередей — ограничивает число попыток доставки одного сообщения. После превышения лимита сообщение автоматически уходит в DLX вместо бесконечного requeue. Это специфичный для quorum-очередей механизм защиты от poison messages. - Продуманная схема retry — DLQ как «карантин для ручного разбора» (простейший вариант) или DLQ с TTL и возвратом в основную очередь (паттерн retry с задержкой). Схема зависит от характера ошибок: временные (недоступность БД) — retry с задержкой; постоянные (некорректные данные) — карантин + алерт.
- Лимиты очередей (max-length / TTL) там, где уместно — защита от неограниченного роста при деградации consumer.
Клиент и подключение
- Клиент знает все узлы кластера — список всех AMQP-эндпоинтов в конфиге клиента, либо балансировщик (HAProxy, облачный LB) перед кластером. Клиент, знающий только один адрес, превращает этот узел в SPOF: при его падении клиент получает «connection refused» и не переключается на выживших, даже если кластер жив.
- Логика reconnect с перебором узлов — при «connection refused» клиент перебирает список узлов, а не зацикливается на одном. В demo-стенде это реализовано через
rabbit.Connectс несколькими URL через запятую.
Мониторинг и эксплуатация
- Плагин
rabbitmq_prometheusвключён —rabbitmq-plugins enable rabbitmq_prometheus, порт 15692. -
prometheus.return_per_object_metrics = true— детализация по каждой очереди. Трейдофф: больший объём данных на скрейп, зато алерты и дашборды работают на уровне конкретных очередей. - Scrape всех нод, а не только одной — потеря ноды должна отражаться в Prometheus как
up == 0. - Алерты настроены минимум по следующим условиям:
- длина очереди растёт монотонно дольше N минут;
- unacked-сообщений больше порога или consumer lag растёт;
- нода ушла из кластера (Prometheus видит UP < 3);
- приближение к memory/disk watermark на любой ноде;
- quorum-очередь без лидера или с числом онлайн-реплик меньше большинства.
- Для multi-region — Federation или Shovel по сценарию: Federation для прозрачной репликации потока событий между регионами, Shovel для точечной перекачки между конкретными очередями/exchange.
Заключение серии
Серия «Высокодоступный RabbitMQ» строилась вокруг одной идеи: кластеризация ≠ HA. Кластер создаёт инфраструктуру репликации, но данные защищают тип очереди, гарантии на стороне клиентов и продуманная операционная модель.
Путь, который мы прошли:
-
Отказоустойчивый RabbitMQ: quorum-очереди и failover без потерь — почему одна нода не вариант, как устроен Raft в quorum-очередях, почему mirrored queues удалены в 4.x и как развернуть кластер, переживающий падение ноды.
-
Не потерять сообщение в RabbitMQ: durability, confirms, ack и DLQ — три уровня durability, publisher confirms против тихих потерь, manual ack и prefetch, Dead Letter Queue и паттерн retry с задержкой.
-
Связываем кластеры RabbitMQ: Federation и Shovel — когда одного кластера мало, как Federation реализует подписку downstream на upstream, чем Shovel отличается по модели и как строить geo-распределение и DR.
-
Эксплуатация RabbitMQ: мониторинг и продакшн-чеклист (эта статья) — плагин
rabbitmq_prometheus, ключевые метрики, дашборд Grafana для наблюдения за failover и полный чеклист продакшн-настроек.
Demo-стенд к серии — khorost-tech/digital-cookbook → rabbitmq/ha-cluster: три ноды RabbitMQ 4.x, Go-клиенты с producer confirms и manual ack, Prometheus + Grafana с готовым дашбордом. Все сценарии из серии воспроизводимы одной командой docker compose up -d.

Комментарии