Это первая статья серии «Высокодоступный RabbitMQ». В обзорной статье о выборе брокера мы разобрали, что RabbitMQ, Kafka и NATS — это не «три вкуса одного», а три разных класса компромиссов. RabbitMQ — broker с очередями, сложной маршрутизацией и явной delivery semantics. Теперь разберём главный практический вопрос: как сделать так, чтобы этот broker пережил падение ноды и не потерял сообщения.
Ответ не в самом факте кластеризации — в правильном типе очереди и корректных гарантиях на стороне клиентов. Кластер создаёт инфраструктуру, данные защищает Raft.
В статье
- Проблематика: почему одна нода не вариант
- Mirrored queues: первое решение и его цена
- Что не решается без кворума
- Путь к Raft: quorum queues и трейдофф
- Операции кластера: add/remove нод, управление репликами
- Демонстрация: failover вживую
- Миграция с mirrored queues на quorum
- Чеклист продакшн-настроек
Проблематика: почему одна нода не вариант
RabbitMQ — это брокер с очередями. Клиент отправляет сообщение в exchange, exchange по правилам binding маршрутизирует его в одну или несколько queue, consumer вычитывает из очереди и отправляет ack. Только после ack брокер удаляет сообщение.
Пока нода одна — это просто: все данные на месте, клиент знает один адрес. Но нода падает. И тут обнаруживается, что очередь жила ровно на этой ноде. Нет ноды — нет очереди, нет данных. Это SPOF (single point of failure) в чистом виде.
Кластер RabbitMQ — несколько Erlang-нод, объединённых в единое логическое пространство. Что кластер реплицирует автоматически:
- метаданные: users, vhosts, exchanges, bindings, policies, parameters — они есть на всех нодах;
- таблицу маршрутизации.
Что кластер не реплицирует автоматически:
- содержимое classic-очередей — сообщения живут только на той ноде, где очередь объявлена.
Это ключевое заблуждение при первом знакомстве с RabbitMQ: «кластер = HA». Нет. Кластеризация ≠ HA. Кластер даёт инфраструктуру репликации, но данные защищает тип очереди.
Сравнение с Kafka: разные классы компромиссов
Часто спрашивают: «Kafka надёжнее?» Это неправильный вопрос. Это разные модели.
Kafka — лог-ориентированная репликация: данные живут в партициях (append-only log), реплицируются через ISR (in-sync replicas), консюмеры читают по смещению. Лог по природе своей хранится и реплицируется как единое целое.
RabbitMQ — очередь-ориентированная модель: данные удаляются после ack, маршрутизация сложная (exchanges, bindings, routing keys), потребитель получает «свою» порцию работы и подтверждает. Это другая семантика, не хуже и не лучше — просто для других задач.
Проблема HA у RabbitMQ не в том, что «он ненадёжный», а в том, что очередь — это состояние, которое надо явно реплицировать, тогда как в Kafka репликация встроена в базовую абстракцию (партицию).
graph TD
C["Клиент\n(знает ВСЕ узлы:\n5672 / 5673 / 5674)"]
subgraph Cluster["Кластер RabbitMQ"]
R1["rabbit@rabbit1\nAMQP :5672"]
R2["rabbit@rabbit2\nAMQP :5673"]
R3["rabbit@rabbit3\nAMQP :5674"]
end
C -->|"publish / consume"| R1
C -->|"failover"| R2
C -->|"failover"| R3
R1 <-->|"метаданные\n+ Raft-репликация"| R2
R2 <-->|"метаданные\n+ Raft-репликация"| R3
R1 <-->|"метаданные\n+ Raft-репликация"| R3
style C fill:#f9f3e3,stroke:#8b7355
style R1 fill:#c9e4c5,stroke:#5b8a5e
style R2 fill:#c9e4c5,stroke:#5b8a5e
style R3 fill:#c9e4c5,stroke:#5b8a5e
Важный нюанс с клиентом. Кластеризация даёт HA на уровне данных, но не на уровне клиента автоматически. Если клиент знает только один адрес (localhost:5672), этот узел становится SPOF на стороне клиента: при его падении клиент получает «connection refused» и не может переключиться на выживших, даже если кластер живёт. Решение — передать клиенту список всех узлов или поставить перед кластером балансировщик (HAProxy, облачный LB).
Mirrored queues: первое решение и его цена
До версии 4.0 RabbitMQ решал проблему репликации данных через classic mirrored queues. Идея простая: очередь имеет master на одной ноде и mirrors (зеркала) на других. Настраивается политикой ha-mode:
# На RabbitMQ 3.13 — политика «зеркалировать на все ноды»
rabbitmqctl set_policy ha-all "^orders\." \
'{"ha-mode":"all","ha-sync-mode":"automatic"}' \
--apply-to queues
При падении master один из mirrors становился новым master. На первый взгляд — решение рабочее.
На практике механизм оказался проблемным по нескольким причинам.
Дорогая синхронизация. При присоединении новой mirror-ноды (или после рестарта) очередь должна синхронизироваться полностью. Если очередь большая, это блокирующая операция: очередь недоступна для записи пока идёт sync. Опция ha-sync-mode: automatic делает это автоматически, но не решает стоимость синхронизации.
Поведение при сетевых разделах. При network partition алгоритм выбора нового master у mirrored queues не опирался на формальный консенсус. В некоторых краевых сценариях (особенно при сложных разделах сети) подтверждённые сообщения могли теряться. Это не теоретическая проблема — разработчики RabbitMQ фиксировали такие случаи в production.
Нагрузка на кластер. Режим ha-mode: all означает зеркалирование на все ноды. В кластере из 5 нод — 5 копий каждого сообщения. Это избыточно и дорого. ha-mode: exactly с числом зеркал лучше, но логика выбора master по-прежнему не формальная.
В результате в RabbitMQ 4.0 classic mirrored queues удалены полностью. Политика ha-mode в 4.x игнорируется — не зеркалирует ничего, просто не работает. Если вы применяете ha-mode к RabbitMQ 4.x, вы получаете ложное чувство безопасности.
Что не решается без кворума
Mirrored queues при всей своей очевидности не решали фундаментальных проблем распределённых систем.
Split-brain без кворума. При сетевом разделе (network partition) две части кластера могут независимо считать себя master. Оба master’а принимают сообщения, подтверждают их клиентам. После восстановления связи обнаруживается, что данные расходятся. Какую копию считать «правдой»? В mirrored queues этот вопрос решался эвристиками, а не формальным алгоритмом.
Отсутствие строгих гарантий порядка. В distributed системе без консенсуса порядок операций не гарантирован при failover. Новый master мог видеть подмножество сообщений, которые видел старый.
Exactly-once недостижимо без кворума. Exactly-once в распределённой системе — это комбинация: идемпотентность producer + transactional semantics (транзакционная семантика записи) + идемпотентность consumer. Без строгого консенсуса на уровне хранилища это нереализуемо. At-least-once + идемпотентная обработка — практичный ответ.
Операционные грабли. ha-sync-mode: manual означает, что синхронизация новых зеркал не происходит автоматически. Администратор должен запускать её вручную. Забыли — новая mirror нода не синхронизирована, при failover на неё данные потеряны. ha-sync-mode: automatic решает это, но с ценой недоступности при синхронизации больших очередей.
CAP-теорема в контексте RabbitMQ: кластер — это распределённое stateful-хранилище. Нельзя одновременно гарантировать Consistency, Availability и Partition tolerance. Quorum queues осознанно выбирают CP: при сетевом разделе меньшинство нод теряет Raft-кворум и не может коммитить записи в quorum-очередь или метастор Khepri — это inherent-свойство Raft-консенсуса, а не настройка. Потеря доступности меньшинства — осознанный размен ради согласованности данных.
Путь к Raft: quorum queues и трейдофф
Версия RabbitMQ важна. Материал и demo-стенд проверены на RabbitMQ 4.3. Поведение существенно зависит от версии: в 4.0 classic mirrored queues удалены полностью; в 4.3 удалены стратегии partition handling (
pause_minority,autoheal,ignore) — ключcluster_partition_handlingпринимается, но не имеет эффекта. Если вы работаете с более ранней версией, сверяйтесь с документацией своей ветки.
Quorum Queue — реплицируемая очередь на основе протокола консенсуса Raft. Это рекомендованный и основной тип очереди в RabbitMQ 4.x для сценариев, где важна сохранность данных.
(rabbit1) participant F1 as Follower
(rabbit2) participant F2 as Follower
(rabbit3) P->>L: publish(msg) L->>F1: replicate(entry) L->>F2: replicate(entry) F1-->>L: ack Note over L,F1: Кворум достигнут (2 из 3) L-->>P: publisher confirm ✓ Note over F2: F2 может отстать —
сообщение уже зафиксировано Note over L: Leader падает F1->>F1: Raft-выборы F1->>F2: Raft-выборы Note over F1: F1 становится новым лидером P->>F1: переподключение, publish продолжается
sequenceDiagram
participant P as Producer
participant L as Leader
(rabbit1)
participant F1 as Follower
(rabbit2)
participant F2 as Follower
(rabbit3)
P->>L: publish(msg)
L->>F1: replicate(entry)
L->>F2: replicate(entry)
F1-->>L: ack
Note over L,F1: Кворум достигнут (2 из 3)
L-->>P: publisher confirm ✓
Note over F2: F2 может отстать —
сообщение уже зафиксировано
Note over L: Leader падает
F1->>F1: Raft-выборы
F1->>F2: Raft-выборы
Note over F1: F1 становится новым лидером
P->>F1: переподключение, publish продолжается
Как устроено
У quorum-очереди есть набор реплик на разных нодах кластера. Одна реплика — лидер (leader), остальные — последователи (followers). Все операции (publish, ack) проходят через лидера. Лидер реплицирует записи в журнал последователей.
Запись считается зафиксированной (committed), когда её подтвердило большинство (quorum) реплик. Для 3 реплик это 2, для 5 — 3.
Если падает нода-лидер, оставшиеся реплики через Raft-выборы (секунды) выбирают нового лидера из последователей. Клиенты переподключаются к живой ноде, очередь продолжает работать. Уже зафиксированные сообщения не теряются — в этом весь смысл кворума.
Нечётное число нод — это не рекомендация, это требование
Нечётность реплик (3 или 5) даёт однозначное большинство:
- 3 реплики → кворум 2 → переживает отказ 1 ноды
- 5 реплик → кворум 3 → переживает отказ 2 нод
- 2 или 4 реплики → при равном разделении невозможно выбрать большинство → выборы зависнут
Минимум для production — 3 ноды.
Кворум Raft и защита от split-brain
В RabbitMQ 4.3 старый механизм cluster_partition_handling = pause_minority удалён — ключ принимается, но не имеет эффекта. Он относился к эпохе Mnesia и classic mirrored queues (удалены в 4.0); в 4.3 его рекомендуется убрать из конфигов.
Защита от split-brain теперь является inherent-свойством Raft: при сетевом разделе ноды, оказавшиеся в меньшинстве (например, 1 из 3), теряют Raft-кворум и физически не могут коммитить записи — ни в quorum-очередь, ни в метастор Khepri. Без кворума лидер не может подтвердить запись клиенту; меньшинство просто прекращает обслуживать запросы до восстановления связи с большинством.
Split-brain невозможен by design: чтобы зафиксировать запись, нужно большинство реплик. Две изолированные части кластера не смогут независимо изменять одни и те же данные — у обеих не будет кворума одновременно.
Цена — временная недоступность меньшинства. Для очереди сообщений это правильный размен: лучше получить «connection refused» и повторить, чем потерять подтверждённые данные.
Трейдофф: память, диск, латентность
Quorum queues требуют хранить копии на каждой реплике. Для кластера из 3 нод — 3 копии всех сообщений. Это не оптимально по месту, но предсказуемо по поведению.
Латентность: каждый publish ждёт подтверждения от большинства реплик перед отправкой confirm клиенту. Это добавляет сетевой round-trip внутри кластера. В локальной сети — миллисекунды. При geo-распределённом кластере (например, разные ДЦ) — это заметно. Для geo-HA используют Federation или Shovel, а не один растянутый кластер.
Как объявить quorum-очередь
Тип задаётся аргументом x-queue-type=quorum при объявлении:
ch.QueueDeclare("demo.orders", true, false, false, false, amqp.Table{
"x-queue-type": "quorum",
})
Либо задать умолчание на уровне vhost — тогда аргумент при declare не нужен:
{
"vhosts": [{
"name": "/",
"metadata": { "default_queue_type": "quorum" }
}]
}
Критичный момент для RabbitMQ 4.x. Тип очереди задаётся только через vhost
default_queue_typeили аргументx-queue-typeпри declare. Управлять типом через policy-ключqueue-typeв 4.x невалидно — такой ключ политики не поддерживается. Это частая ошибка при миграции с материалов под 3.x. Не пытайтесь «навесить тип очереди политикой».
Операции кластера: add/remove нод, управление репликами
Сборка кластера
Для кластеризации нужны три компонента:
-
Общий Erlang cookie на всех нодах — «пароль» для межнодового взаимодействия:
# docker-compose.yml environment: RABBITMQ_ERLANG_COOKIE: "DEMOCOOKIE0123456789" -
Стабильные hostname — ноды адресуются как
rabbit@<hostname>:hostname: rabbit1 -
Конфигурация peer discovery:
# rabbitmq.conf cluster_formation.peer_discovery_backend = classic_config cluster_formation.classic_config.nodes.1 = rabbit@rabbit1 cluster_formation.classic_config.nodes.2 = rabbit@rabbit2 cluster_formation.classic_config.nodes.3 = rabbit@rabbit3 # cluster_partition_handling — в RabbitMQ 4.3 удалён, не нужен. # Поведение при сетевом разделе определяется Raft-кворумом автоматически.
Ручное добавление и удаление нод
# Добавить ноду в кластер (выполняется на добавляемой ноде):
rabbitmqctl stop_app
rabbitmqctl join_cluster rabbit@rabbit1
rabbitmqctl start_app
# Проверить состав кластера:
rabbitmqctl cluster_status
# Безопасно удалить ноду из кластера (выполняется на других нодах):
rabbitmqctl forget_cluster_node rabbit@rabbit3
При удалении ноды убедитесь, что на ней нет реплик quorum-очередей, которые опустятся ниже кворума. Иначе очереди станут недоступны.
Управление репликами quorum-очередей
Фактор репликации задаётся при создании очереди аргументом x-quorum-initial-group-size:
# Создать очередь с 5 репликами (если аргумент не задан, реплики размещаются
# исходя из размера кластера; на проде обычно используют нечётное число — 3 или 5):
rabbitmqadmin declare queue --name=critical.orders --type=quorum \
--arguments='{"x-quorum-initial-group-size": 5}'
После создания репликами можно управлять через rabbitmq-queues:
# Равномерно перебалансировать лидеров между нодами:
docker exec rabbit1 rabbitmq-queues rebalance quorum
# Добавить реплику очереди на конкретную ноду:
docker exec rabbit1 rabbitmq-queues grow rabbit@rabbit3 all
# Точечно добавить/удалить реплику:
docker exec rabbit1 rabbitmq-queues add_member --vhost / demo.orders rabbit@rabbit3
docker exec rabbit1 rabbitmq-queues delete_member --vhost / demo.orders rabbit@rabbit3
RAM node — устаревший контекст
В старых версиях RabbitMQ существовали RAM nodes — ноды, хранящие метаданные Mnesia только в памяти (для ускорения). RAM node хранит метаданные только в памяти — при рестарте они теряются, и нода переполучает их от соседей. Для quorum-очередей это не даёт выигрыша в производительности, а операционный риск выше; в современном RabbitMQ disk-ноды предпочтительны, RAM node — устаревший нишевый приём. В современном RabbitMQ (4.x) используйте только disk nodes.
Восстановление после отказов
При потере одной ноды из трёх:
- Кластер продолжает работать (2 из 3 нод — большинство).
- Quorum-очереди выбирают нового лидера (секунды).
- После возврата ноды — она автоматически присоединяется и синхронизирует реплики.
Если потеряны 2 из 3 нод (потеря большинства):
- Оставшаяся нода теряет Raft-кворум и прекращает обслуживать запросы к quorum-очередям — она не может коммитить записи без большинства реплик.
- После возврата нод кластер восстанавливается автоматически при наличии кворума.
- Если ноды не вернутся — нужна ручная процедура восстановления (вне scope этой статьи).
Демонстрация: failover вживую
Demo-стенд доступен в репозитории: khorost-tech/digital-cookbook — rabbitmq/ha-cluster.
Стенд включает три ноды RabbitMQ 4.x, Go-клиентов (producer и consumer), Prometheus и Grafana с готовым дашбордом для наблюдения за failover.
Запуск кластера
# Из папки ha-cluster:
docker compose up -d
# Дождаться healthcheck (~40 секунд), проверить состав кластера:
docker exec rabbit1 rabbitmqctl cluster_status
В секции Running Nodes должны быть rabbit@rabbit1, rabbit@rabbit2, rabbit@rabbit3.
Management UI: http://localhost:15672 (логин demo / demo).
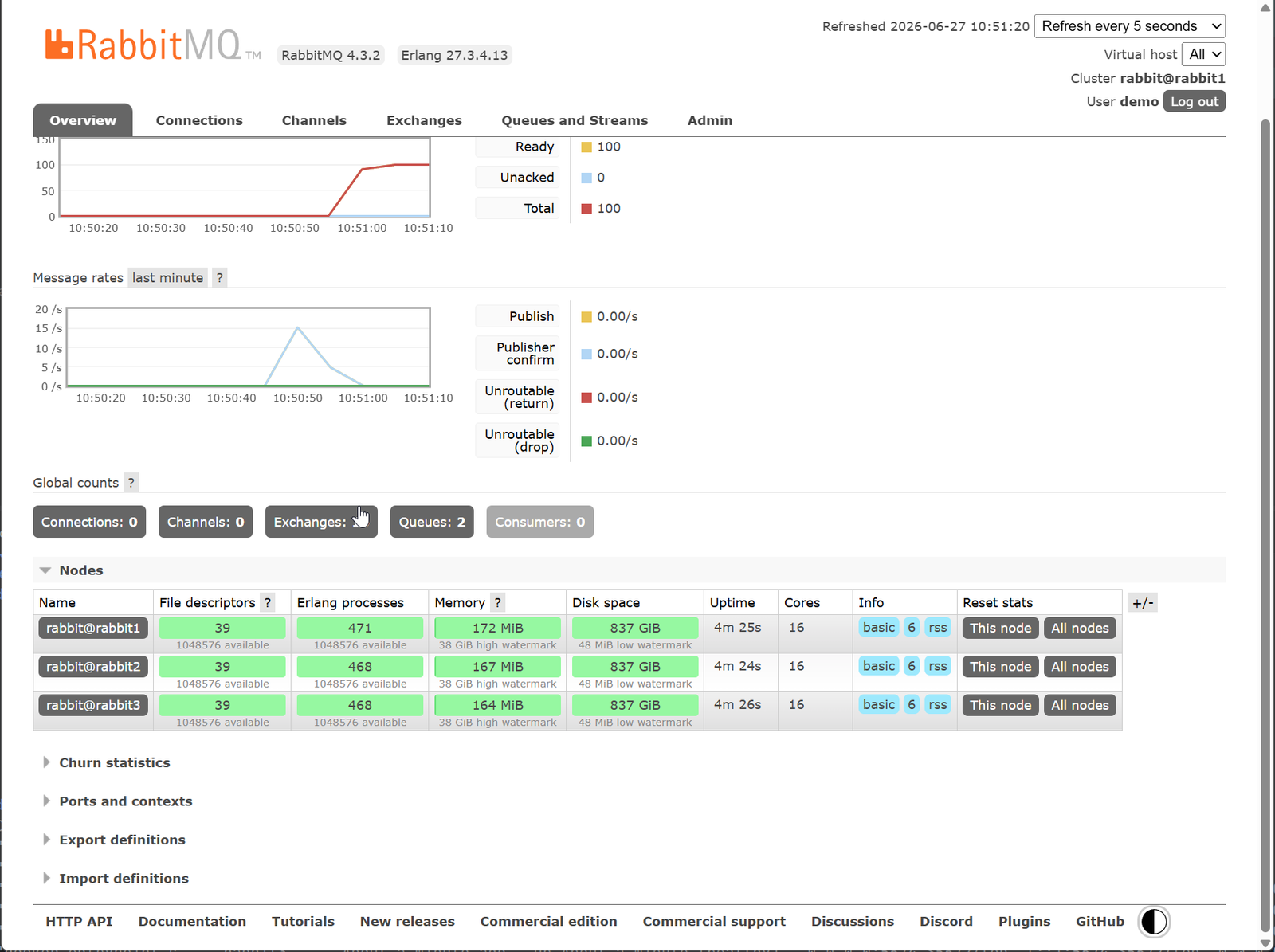
Quorum-очередь в UI
После первого запуска producer очередь demo.orders появится автоматически как quorum. В UI видно: лидер на одной из нод, реплики на всех трёх.
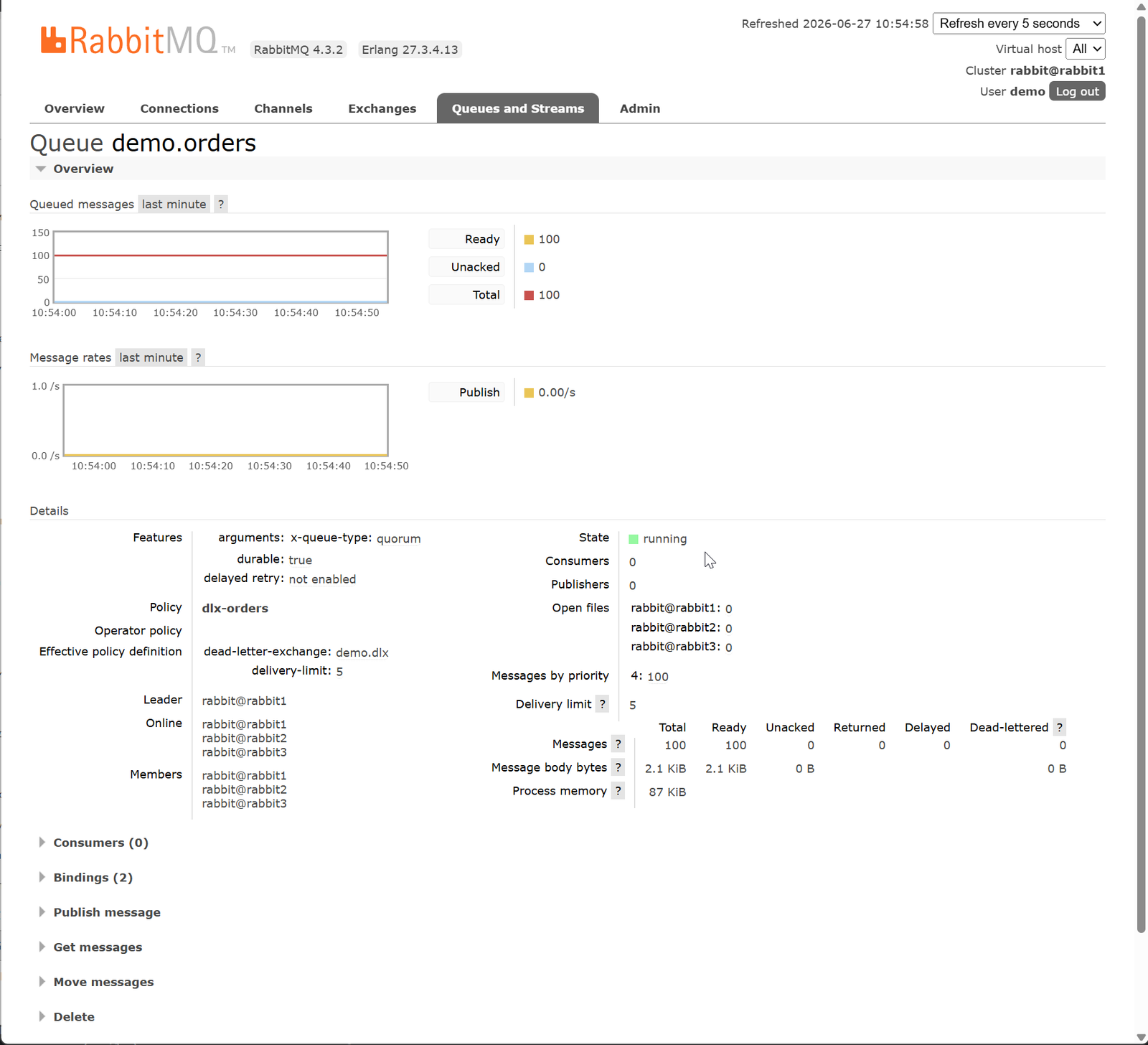
Failover: три терминала
# Терминал 1 — consumer:
cd go && go run ./cmd/consumer
# Терминал 2 — producer (200 сообщений с паузой 50 мс):
cd go && go run ./cmd/producer -n 200
# Терминал 3 — интерактивный failover:
bash scripts/failover.sh
Скрипт failover.sh:
- Показывает текущего лидера
demo.orders. - По нажатию Enter убивает ноду-лидера (
docker kill <container>). - Через 5 секунд показывает нового лидера на другой ноде.
Что происходит:
- Consumer в терминале 1 автоматически переподключается (клиент знает все три эндпоинта) и продолжает получать сообщения.
- Producer с publisher confirms не фиксирует потерь: confirm не пришёл — producer повторит.
- На Grafana-дашборде кратковременный провал publish rate (1–3 секунды переизбрания лидера Raft), затем восстановление. Глубина очереди не обнуляется.
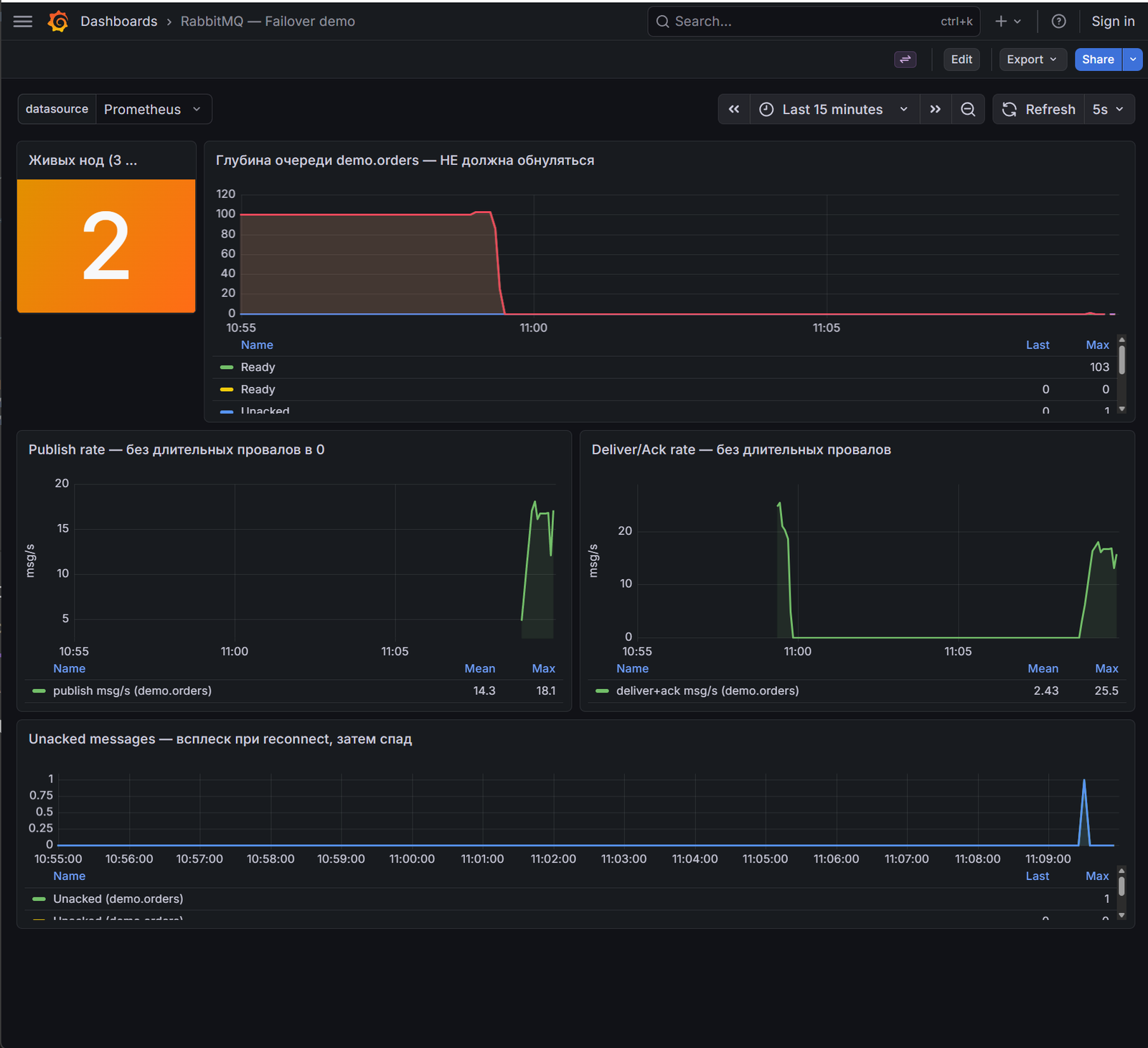
Ключевой обучающий момент про клиента
Producer и consumer запускаются с флагом -urls, содержащим все три эндпоинта:
# По умолчанию клиент знает все три ноды:
go run ./cmd/producer -urls "amqp://demo:demo@localhost:5672/,amqp://demo:demo@localhost:5673/,amqp://demo:demo@localhost:5674/"
Если запустить клиента только с одним адресом (localhost:5672) и убить именно эту ноду — клиент получит «connection refused» и зациклится, даже если кластер живёт. Брокер выжил, клиент умер. Это классическая ловушка: кластеризация даёт HA на уровне данных, а не на уровне клиентского подключения.
Миграция с mirrored queues на quorum
Если у вас RabbitMQ 3.x с mirrored queues и вы переходите на 4.x — нельзя «сконвертировать» classic-очередь в quorum на месте. Это принципиально другой тип с другой внутренней структурой. Миграция — это всегда создание новой очереди.
Порядок миграции
-
Завести новую quorum-очередь с нужным именем или через vhost-умолчание:
# На уровне vhost — все новые очереди будут quorum. # Умолчание типа очереди задаётся через definitions.json (как в demo-стенде) # или через Management API. CLI-синтаксис зависит от версии rabbitmqadmin (v1/v2) # и может различаться — рекомендуется использовать definitions.json или API. -
Переключить consumers на новую очередь, дать вычитать остатки из старой mirrored-очереди.
-
Переключить producers на маршрут в новую очередь.
-
Дождаться опустошения старой очереди, удалить её и снять
ha-policy.
Mirrored demo на RabbitMQ 3.13 (legacy-стенд)
В demo-стенде для демонстрации разницы есть legacy-нода на RabbitMQ 3.13:
# Поднять legacy-стенд (один контейнер rabbit-legacy):
docker compose -f docker-compose.mirrored.yml up -d
# Применить ha-политику (rabbitmqadmin v1, старый синтаксис):
bash scripts/mirrored-demo.sh
Скрипт mirrored-demo.sh написан под rabbitmqadmin v1 (старый позиционный синтаксис с name=..., флаги -u/-p). dlq-demo.sh написан под rabbitmqadmin v2 (новый синтаксис --name, --type, --username). Это не ошибка — v1 и v2 несовместимы по синтаксису, и у каждого скрипта своя целевая версия.
В Management UI legacy (http://localhost:15680) можно увидеть, что у legacy.q есть зеркала. Та же политика ha-mode на 4.x-кластере не даёт ничего — ключ игнорируется.
Чеклист продакшн-настроек
Финальный список — всё, что должно быть проверено перед отправкой кластера в production.
Кластер и реплики:
- Нечётное число нод: 3 или 5. Минимум 3 — для устойчивого Raft-кворума.
- Партиции обрабатываются автоматически: при потере большинства меньшинство не имеет кворума и не обслуживает записи. Отдельная настройка
cluster_partition_handlingв RabbitMQ 4.3 удалена/не нужна — убрать из конфигов. - Общий Erlang cookie, стабильные hostname.
- Все очереди — quorum (
x-queue-type=quorumили vhostdefault_queue_type=quorum). - Тип очереди не задаётся через policy-ключ
queue-type— в 4.x невалидно.
Durability:
- Durable exchange + durable queue + persistent message (
delivery-mode=persistent). - Для quorum-очередей — достаточно durable + quorum: сообщения реплицированы на большинстве.
Гарантии доставки:
- Producer: publisher confirms включены. Nack/timeout — повтор с логированием.
- Consumer: manual ack (
autoack=false). Обработчик идемпотентен. - Разумный prefetch — десятки (не 1 и не «бесконечность»).
- DLX/DLQ настроен;
delivery-limitдля защиты от poison messages.
Клиент:
- Клиент знает все узлы кластера (список в
-urls) или за кластером стоит балансировщик. - Логика reconnect с перебором узлов при «connection refused».
Мониторинг:
-
rabbitmq_prometheusплагин включён. - Алерты: длина очередей, unacked/lag, память/диск watermark, число нод, состояние Raft.
- Grafana-дашборд с метриками по каждой очереди (
prometheus.return_per_object_metrics = true).
В следующей статье серии разберём гарантии доставки глубже: publisher confirms, manual ack, идемпотентность, Dead Letter Queue и паттерн retry с задержкой — «RabbitMQ: durability, DLQ и гарантии доставки».
Комментарии