Когда в системе становится тесно от синхронных HTTP-вызовов, обсуждение быстро скатывается к знакомым словам: RabbitMQ, Kafka, NATS. А иногда к четвёртому: “у нас уже есть Redis, давайте через него”. Дальше обычно начинается выбор по знакомству, по моде или по одному услышанному тезису вроде “Kafka надёжнее”, “RabbitMQ проще”, “NATS быстрее”.
Проблема в том, что это не просто три продукта с разным API. Это три разных класса компромиссов. Если выбрать брокер по общему ощущению, а не по реальной модели нагрузки и доставки, почти наверняка получится система, в которой либо слишком много операционной сложности, либо не хватает нужных гарантий, либо одно и другое сразу.
Здесь не про все команды и тонкости конфигурации, а про инженерный взгляд: какие задачи у этих систем естественные, чем они отличаются по модели, где типовые анти-паттерны и как формулировать требования так, чтобы выбор брокера не превращался в спор по вероисповеданию.
В статье
- С чего начинать выбор брокера
- Когда нужен RabbitMQ
- Когда нужен Kafka
- Когда нужен NATS
- Когда хватит Redis
- Почему один и тот же “асинхронный слой” может означать совершенно разное
- Типичные ошибки выбора
- Надёжность и масштабируемость: на что смотреть сразу
- Короткий checklist перед выбором
С чего начинать выбор брокера
Правильный выбор почти никогда не начинается с названия продукта. Он начинается с вопросов к задаче:
- Это очереди задач, события или поток данных?
- Нужна ли долгая ретенция?
- Нужен ли replay старых событий?
- Нужна ли сложная маршрутизация?
- Какой throughput и какой latency действительно требуются?
- Что происходит при падении одного consumer?
- Что считается успешной доставкой и какая потеря данных допустима?
Если на эти вопросы нет ответа, то и выбор между RabbitMQ, Kafka и NATS будет гаданием.
flowchart TD
A["Нужен асинхронный слой"] --> B{"Что за нагрузка?"}
B -->|"Задачи, маршрутизация,\nwork queues"| C["RabbitMQ"]
B -->|"Долгая ретенция,\nreplay, event backbone"| D["Kafka"]
B -->|"Лёгкий messaging,\nrequest/reply"| E["NATS"]
B -->|"Простая очередь или events,\nRedis уже в стеке"| R["Redis"]
R --> R1{"Какой механизм?"}
R1 -->|"FIFO-задачи"| R2["Lists"]
R1 -->|"Fire-and-forget"| R3["Pub/Sub"]
R1 -->|"Durable events,\nconsumer groups"| R4["Streams"]
style C fill:#c9e4c5,stroke:#5b8a5e
style D fill:#c9e4c5,stroke:#5b8a5e
style E fill:#c9e4c5,stroke:#5b8a5e
style R fill:#f9f3e3,stroke:#8b7355
style R2 fill:#f9f3e3,stroke:#8b7355
style R3 fill:#f9f3e3,stroke:#8b7355
style R4 fill:#f9f3e3,stroke:#8b7355
Когда нужен RabbitMQ
RabbitMQ естественно ложится на сценарии, где важны:
- очереди задач;
- routing;
- fanout, topic и direct semantics;
- consumer acknowledgements;
- сравнительно понятная модель “брокер доставляет сообщение обработчику”.
Он особенно хорош, когда вы хотите не event log, а именно broker с явной delivery semantics и routing model.
Типовые хорошие сценарии:
- фоновые задачи;
- интеграционные очереди;
- команды между сервисами;
- уведомления и fanout по нескольким consumer;
- классический job processing.
RabbitMQ часто выбирают там, где хочется понятной очередной модели и относительно быстрого результата без построения большой streaming-платформы.
Когда нужен Kafka
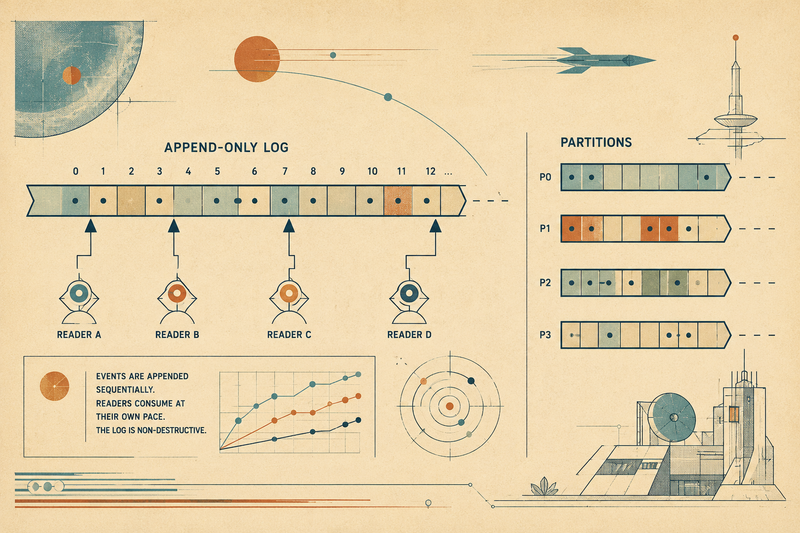
Kafka — это уже не просто “очередь сообщений”. Естественная модель Kafka — это durable event log, который можно читать разными consumer group, хранить, переигрывать и использовать как backbone для data pipelines.
Kafka особенно уместен, когда важны:
- высокая пропускная способность;
- долговременная ретенция;
- replay событий;
- несколько независимых consumer group;
- stream processing и data integration.
Типовые хорошие сценарии:
- event backbone между многими системами;
- CDC и data pipelines;
- аналитические и near-real-time ingestion сценарии;
- stream processing;
- большие интеграционные потоки, где событие живёт дольше одной обработки.
Kafka хорош не потому, что “самый надёжный брокер”, а потому что он решает задачу event log и масштабируемого потокового транспорта лучше, чем классический queue broker.
Когда нужен NATS
NATS особенно силён как лёгкий messaging layer:
- pub/sub;
- request/reply;
- queue groups;
- очень простой operational footprint;
- небольшой latency;
- один бинарник и быстрая развёртка.
С Core NATS это особенно заметно: система получается очень лёгкой и быстрой. Когда нужна persistence, retention и более богатая модель хранения, появляется JetStream.
Типовые хорошие сценарии:
- внутреннее взаимодействие микросервисов;
- request/reply без лишней тяжести;
- событийный слой в небольшой и средней системе;
- edge / distributed deployments, где хочется меньшей operational цены;
- практичные service-to-service patterns без желания тянуть “целую платформу”.
Практически это значит: NATS хорош там, где вам нужен messaging, а не обязательно тяжёлый data platform stack.
Когда хватит Redis
Redis — не брокер сообщений. Но в нём есть три механизма, которые регулярно используют как messaging layer. Это не ошибка, если понимать границы каждого.
-
Lists (LPUSH/BRPOP) — простая FIFO-очередь. Хороша для фоновых задач (письма, ресайз), где потеря при падении consumer допустима. Нет ack, retry, dead-letter queue.
-
Pub/Sub — fire-and-forget broadcast. Подходит для инвалидации кэша и real-time уведомлений. Не хранит ничего: нет подписчика — сообщение исчезает.
-
Streams — append-only лог с consumer groups и acknowledgement, по модели ближе всего к Kafka. Подходит для event distribution и at-least-once доставки. Retention настраивается (
MAXLEN,MINID), но нет partition-level параллелизма и stream processing экосистемы уровня Kafka.
Redis оправдан как messaging layer, когда он уже в стеке, нагрузка умеренная и модель простая. Но это и ловушка: если messaging становится критичным путём, а Redis при этом обслуживает кэш, сессии и rate limiting — одна перегрузка влияет на всё. Сложная маршрутизация — территория RabbitMQ, долгий retention с replay — территория Kafka.
Быстрое сравнение
| RabbitMQ | Kafka | NATS | Redis | |
|---|---|---|---|---|
| Модель | Broker с очередями | Durable event log | Lightweight pub/sub | Lists / Pub/Sub / Streams |
| Ретенция | До подтверждения | Дни — месяцы | Нет¹ | Lists: до чтения. Streams: настраиваемая |
| Replay | Нет | Да | Нет¹ | Только Streams |
| Routing | Exchanges, bindings | По партициям | По subjects | Нет |
| Consumer groups | Да | Да | Да | Только Streams |
| Гарантия | At-least-once | At-least-once | At-most-once¹ | Lists: at-most. Streams: at-least |
| Ops cost | Средняя | Высокая | Низкая | Минимальная |
| Где естественен | Work queues, routing | Event backbone, CDC | Service-to-service | Messaging при наличии Redis |
¹ NATS JetStream добавляет ретенцию, replay и at-least-once — но это уже отдельный слой поверх Core NATS.
Почему один и тот же “асинхронный слой” может означать совершенно разное
На словах часто звучит так: “нам нужен брокер сообщений”. Но за этой фразой могут скрываться очень разные вещи.
Например:
- очередь задач — кто-то должен взять работу и подтвердить её выполнение;
- event distribution — событие должны увидеть несколько независимых потребителей;
- event log — события надо хранить и читать повторно;
- request/reply — нужен не store-and-replay, а быстрый обмен между сервисами;
- stream processing — важен непрерывный поток данных с независимой обработкой.
Именно поэтому заменить одну систему другой “потому что она тоже умеет сообщения” — плохой путь.
flowchart LR
A["Асинхронный слой"] --> B["Work queues"]
A --> C["Event distribution"]
A --> D["Durable log / replay"]
A --> E["Request / reply"]
A --> F["Streaming pipelines"]
A --> G2["Простые фоновые задачи"]
B --> G["RabbitMQ чаще естественен"]
C --> H["RabbitMQ, NATS или Redis Streams"]
D --> I["Kafka чаще естественен"]
E --> J["NATS особенно удобен"]
F --> K["Kafka или JetStream"]
G2 --> L["Redis Lists, если Redis уже есть"]
Типичные ошибки выбора
1. Выбирать по одному красивому тезису
Примеры плохих тезисов:
- “Kafka надёжнее, значит берём Kafka”;
- “RabbitMQ попроще, значит хватит его”;
- “NATS очень быстрый, значит он нам точно подходит”.
Каждый из этих тезисов может быть частично верным и всё равно приводить к неправильному выбору.
2. Подменять event log обычной очередью
Если вам нужен replay, долгая ретенция и независимые consumer group, классическая очередь задач обычно не покрывает реальную модель. В этом месте попытка “сделать как-нибудь через RabbitMQ” часто приводит к борьбе с системой.
3. Тянуть Kafka туда, где нужна просто очередь задач
Это другая крайность: вместо понятного job queue появляется большая платформа с более дорогой эксплуатацией, а бизнес-задача при этом остаётся очень скромной.
4. Считать, что NATS “просто заменяет всё”
NATS действительно очень силён в своём профиле. Но это не значит, что всякая heavy-duty event platform автоматически должна быть заменена на него без анализа retention, replay и операционных требований.
5. Не считать операционную цену
Выбор брокера — это не только API и модель доставки. Это ещё:
- деплой;
- мониторинг;
- backup и recovery;
- обновления;
- клиентские библиотеки;
- поведение при частичных сбоях;
- нагрузочные тесты;
- компетенции команды.
Слишком тяжёлая система для простой задачи так же вредна, как и слишком простая система для сложной нагрузки.
Надёжность и масштабируемость: на что смотреть сразу
У всех трёх систем вопрос надёжности выглядит по-разному, но набор правильных вопросов похож:
- где хранится состояние;
- как устроена репликация;
- что считается подтверждённой доставкой;
- что можно потерять при отказе;
- как устроен failover;
- как масштабируется чтение и запись;
- что происходит при перегрузке одного consumer или узла.
Практически:
- RabbitMQ чаще требует думать в терминах очередей, ack, prefetch и routing topology;
- Kafka — в терминах partitions, retention, replication factor, consumer groups и replay;
- NATS — в терминах Core vs JetStream, durability, stream configuration и operational simplicity vs guarantees.
То есть “надёжность” у них не одна и та же. Это не общий флажок в сравнительной таблице, а разные модели компромисса.
Короткий checklist перед выбором
Перед тем как выбрать брокер, полезно ответить на несколько вопросов:
- Нужна очередь задач, event distribution или durable event log?
- Нужна ли долгая ретенция и replay?
- Нужна ли сложная маршрутизация?
- Какой throughput и latency действительно требуются?
- Какая потеря данных допустима?
- Что команда уже умеет сопровождать?
- Что дешевле для этой задачи: более сложная платформа или более простой брокер с понятными ограничениями?
Если эти ответы есть, выбор между RabbitMQ, Kafka и NATS обычно становится заметно проще и спокойнее.
Итог
RabbitMQ, Kafka, NATS и Redis — это не “четыре вкуса одного и того же”. У них пересекаются некоторые сценарии, но сильные стороны разные:
- RabbitMQ — задачи, очереди, сложная маршрутизация;
- Kafka — durable event log, replay, потоковые data pipelines;
- NATS — лёгкий, быстрый messaging layer и service-to-service взаимодействие;
- Redis — простой messaging “из того, что уже есть”: Lists для очередей, Streams для event distribution, Pub/Sub для real-time уведомлений.
Redis удобен именно тем, что он часто уже в стеке. Но это же и его ловушка: “уже есть” не означает “подходит”. Если messaging становится критичной частью системы, Redis перестаёт быть бесплатным бонусом и начинает конкурировать за ресурсы с кэшем и сессиями.
Самая дорогая ошибка здесь — не “выбрать не тот продукт по рейтингу”, а не сформулировать задачу, которую этот продукт должен решать. Если начать с модели данных, доставки, ретенции и отказов, выбор брокера перестаёт быть спором по моде и становится нормальным инженерным решением.
Документация и первоисточники
Для этой статьи я опирался на официальные материалы:

Комментарии